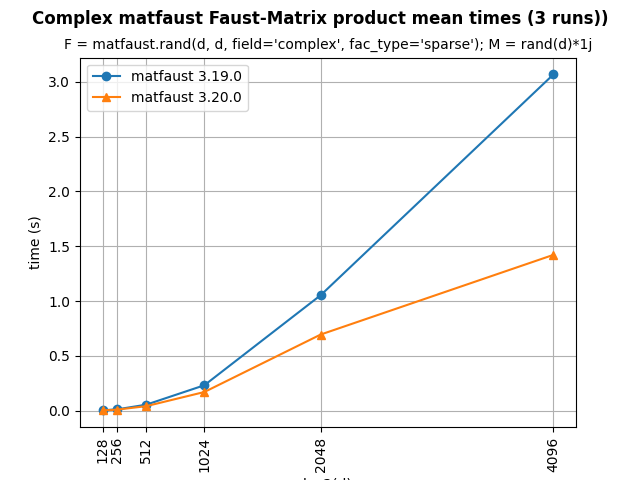
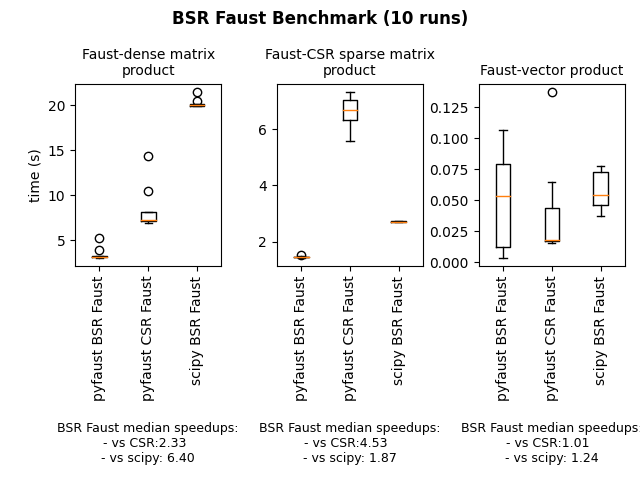
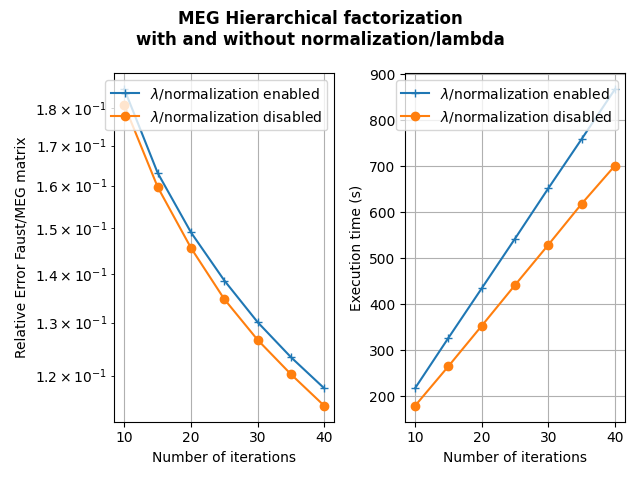
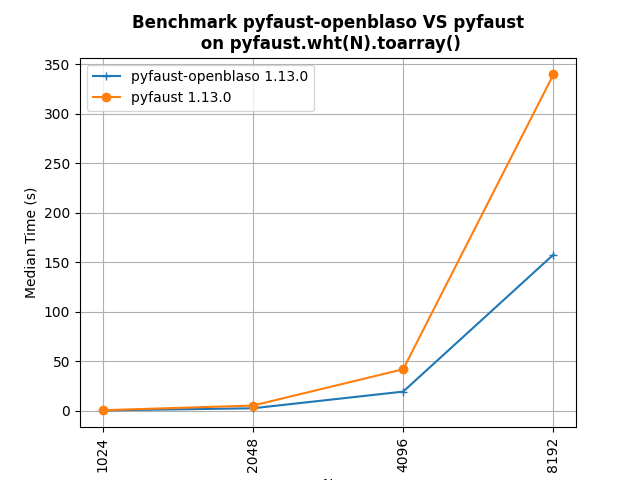
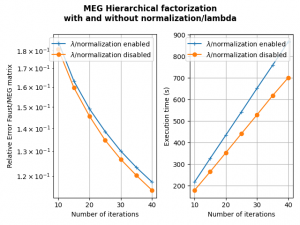
This version adds the option no_lambda in the hierarchical and PALM4MSA algorithms. It allows to fix lambda to 1 in the overall algorithm without any update (and no lambda gradient calculation). Associated with the no_normalization parameter, it accelerates the algorithm without necessarily reducing the precision of the Faust approximate as the first figure below shows for the MEG matrix factorization (parameterized as shown in API doc here, section 3. along with the no_normalization and no_lambda parameters to True).
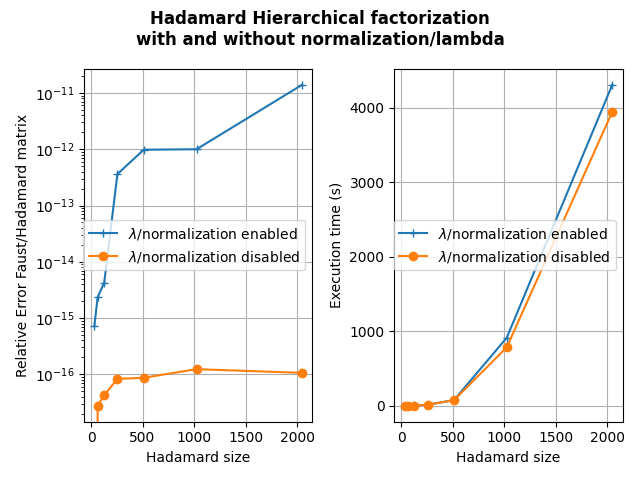
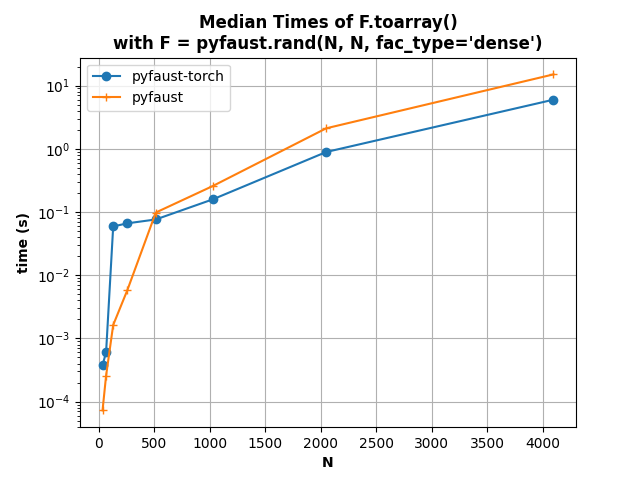
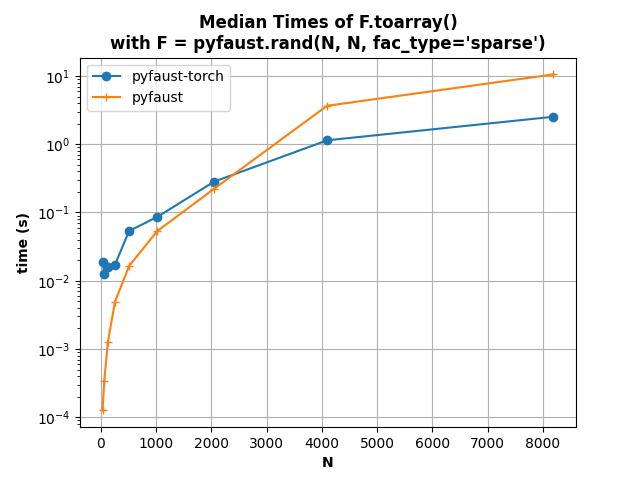
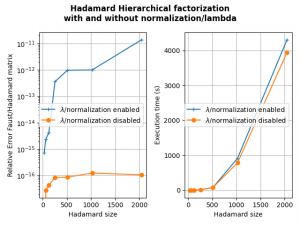
 The second figure shows that disabling the normalization and keeping lambda to 1 allows also to obtain a good Faust approximate of a Hadamard matrix (actually better than with normalization and seemingly more stable when increasing the Hadamard matrix size).
The second figure shows that disabling the normalization and keeping lambda to 1 allows also to obtain a good Faust approximate of a Hadamard matrix (actually better than with normalization and seemingly more stable when increasing the Hadamard matrix size).
 Note: the options
Note: the options no_lambda and no_normalization are only available with the 2020 implementations of PALM4MSA and the hierarchical algorithm.
Note: This is an experimental work that needs further theoretical considerations.